Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
Google updates Gemini 2.5 Pro model for coders | InfoWorld
Technology insight for the enterpriseGoogle updates Gemini 2.5 Pro model for coders 6 May 2025, 11:58 pm
Google has updated its Gemini 2.5 Pro AI model with stronger coding capabilities, hoping developers would begin building with the model before the Google I/O developer conference later this month.
Released May 6, Gemini 2.5 Pro Preview (I/O edition) is accessible in Google AI Studio tool and in Vertex AI.
Commenting on the update, Google said developers could expect meaningful improvements for front-end and UI development alongside improvements in fundamental coding tasks including transforming and editing code and building sophisticated agentic workflows. Developers already using Gemini 2.5 Pro will find not only improved coding performance but reduced errors in function calling and improved function calling trigger rates, the company said.
The Gemini 2.5 Pro model shines for use cases such as video to code, due to the model’s “state-of-the-art video understanding,” and offers easier web feature development, due to the model’s “best-in-class front-end web development,” Google said.
{kind=link}
IBM updates watsonx Orchestrate with new agent-building capabilities 6 May 2025, 6:22 pm
IBM has updated its AI platform for workflow and task automation, watsonx Orchestrate (WXO), with new agent-building and observability capabilities to help developers more quickly build agents that can take on repetitive tasks in the enterprise.
CEO Arvind Krishna said the updates underpin the company’s shift from AI assistants to AI agents for workflow and task automation. The company is aiming to capture a larger share of the market for building generative AI applications as enterprises double their AI investments over the next few years, he said at a media briefing ahead of the company’s annual Think conference.
Agentic AI applications that can complete tasks without manual intervention while learning from new data are attracting the attention of enterprises looking to automate more work.
“We’re now evolving the capabilities of WXO to easily build, deploy and manage all your agentic AI systems within a simple and unified user experience optimized to scale,” an IBM spokesperson said.
watsonx Orchestrate gets new agent building tools
Watsonx Orchestrate (WXO) is part of the broader watsonx portfolio of tools, automations, assistants, and other integrations. One of the newest WXO components is Agent Builder, a no-code studio that enables the creation of agents with drag and drop tools. “The studio will also allow developers to import outside tools and automations such as open source frameworks, third party or custom tools and automations to build a custom agent,” an IBM spokesperson said.
IBM is not the first to offer no-code tools for agent creation: Salesforce, AWS, Microsoft, and Google, among others, already have similar offerings.
Gartner vice president analyst Jim Hare sees developers mostly staying in their lane with these tools: “It is unlikely that watsonx Orchestrate will get traction outside of customers already part of the IBM ecosystem and already using other IBM products including other watsonx products,” he said. “There might be few exceptions —customers who are in requirement of a hybrid, on-prem, or edge deployment.”
Other additions to WXO include a new agent development kit (ADK) that professional developers can use to create highly specialized agents from scratch.
There again, IBM is not alone in offering such capabilities. Last month at Cloud Next, Google introduced a new open source framework under the same name, Agent Development Kit, which it said will enable developers to build an AI agent in under 100 lines of Python code.
Pre-built agents and the Agent Catalog inside watsonx Orchestrate
IBM is also adding over 150 pre-built agents to WXO via the new Agent Catalog. It developed some itself, while others are from partners including Box, MasterCard, Oracle, Salesforce, and ServiceNow, the IBM spokesperson said.
The agents can be embedded in systems for web research, performing calculations, or other tasks, and also can be used as templates for creating new agents in Agent Builder, the spokesperson added.
IBM said it plans to offer revenue sharing agreements to supporting partners for agents they build with WXO and publish in the catalog, but didn’t provide details.
This is another area in which IBM is playing catch-up: Vendors including Salesforce, ServiceNow, and Microsoft already offer such marketplaces with their agent-building platforms.
Multi-agent orchestrator inside watsonx Orchestrate
IBM has made changes throughout WXO to enable orchestration of multiple agents, whether they were built by IBM, a customer, or a third party.
“Think of it as an agent supervisor capability which analyzes user requests, routes tasks to the correct agents and allows them to share information and tackle complex, multi-step processes together,” the IBM spokesperson said.
Other additions to WXO include a set of observability tools to help developers monitor their agents, IBM said. These tools include capabilities for monitoring AI performance, reliability, and enforcing AI guardrails, it said.
Watsonx Orchestrate is generally available with pricing based on consumption. For clients just starting out with WXO, the “Essentials” version offers entry-level pricing, IBM said.
{kind=link}
Static analysis proposed for shell programs 6 May 2025, 6:09 pm
Semantics-driven static analysis is being proposed by a group of researchers as way to ensure that Unix, Linux, and macOS shell programs are safe, bug-free, and work as expected. However, the effort faces unique challenges, due to the shell’s “pervasive dynamicity” and “opaque, polyglot commands.”
The researchers from Brown University, Stevens Institute of Technology, Rice University, and UCLA make their case in a newly published paper, “From Ahead-of- to Just-in-Time and Back Again: Static Analysis for Unix Shell Programs.” The authors stress that shell programming is as prevalent as ever but is quite complex due in part to the structure of shell programs, their use of opaque software components, and their complex interactions with the broader environment. Even when being extremely careful, shell developers discover devastating bugs in their programs only at runtime. At best, shell programs going wrong crash the execution of a long-running task; at worst, they silently corrupt the broader execution environment, affecting user data, modifying system files, and rendering entire systems unusable, the paper notes. The paper then asks if shell users could enjoy the benefits of semantics-driven static analysis before their programs’ execution, as offered by most other production languages? These benefits would extend to users of Linux, the BSD operating systems (FreeBSD, OpenBSD, and NetBSD), macOS, and anywhere the shell is used including containers and Windows Subsystem for Linux.
Shell scripting is very common, as the shell remains the glue that holds modern systems together; modern facilities such as continuous integration and continuous delivery (CI/CD) are often written in shell, said paper co-author Nikos Vasilakis, from Brown University, in an emailed response to questions. Other popular environments used for tasks such as building software, serving machine learning workloads, and provisioning the cloud are all thin wrappers around scripts, Vasilakis added. However, the shell language does not behave like other languages, he said. This leaves both inexperienced and seasoned users making many mistakes, with these mistakes tending to be catastrophic. “And because the shell is an old language, it lacks many of the facilities we’ve come to expect in modern languages,” Vasilakis said. “What’s more, the shell is used to manipulate programs on files on live systems. Mistakes can cause data corruption, service interruption, irreversible data loss, and leakage of sensitive user information.”
Static analysis is a proven technique for knowing things about a program before it runs, according to Vasilakis. “A good static analysis can detect many bugs before they have the chance to bite,” he said. By being semantics-driven, the analysis targets deeper reasoning than, say, a syntactic linter, Vasilakis explained. Several kinds of analyses are envisioned, operating in tandem to tackle intricacies of a complex environment. For example, an effect analysis targets file system interactions while a type system centered around regular types targets interprocess interactions in the pipe-and-filter computations. “The goal is to provide precise error messages before the execution of a program, similar to what you’d expect from a modern programming language,” Vasilakis said.
The hope is that semantic analysis will discover more and deeper bugs by being able to reason deeply about shell scripts, the programs they invoke, the way they interact, and what they do to the file system. The researchers are currently implementing several systems that tackle parts of their vision, Vasilakis said. “We have to build up our stream reasoning engine, a symbolic execution engine targeting effects, a specification language for Unix and Linux commands, and semantic models so that we can be confident that our analysis is correct,” he said. “Several more papers and public tools will be available very soon.”
For now, everyone using the shell should be aware of shellcheck, a syntactic—rather than semantic—static analysis for shell scripts, Vasilaskas said. “Our hope is that a semantic analysis will help discover more and deeper bugs—by being able to reason deeply about shell scripts, the programs they invoke, the way they all interact, and what they do to the file system.” Some of these mistakes are in the same category as what shellcheck can catch, but others, such as finding misuses of the file system or command composition mistakes several commands “away,” will be new, he said.
In the meantime, Vasilakis suggested interested parties use the try tool, which will not catch bugs in advance but will limit the “blast radius” of mistakes.
{kind=link}
Using AI-powered email classification to accelerate help desk responses 6 May 2025, 11:00 am
Service-based organizations may handle thousands of customer emails daily, placing a significant burden on IT help desks, customer service organizations, and other departments involved in reading, prioritizing, and responding to those communications. A 2023 study found that mid-size and larger companies handling customer inquiries often struggle with response delays, impacting customer satisfaction and retention.
Accurate classification and prioritization of emails are critical for improving response time and customer satisfaction. By leveraging machine learning—specifically text classification and sentiment analysis—organizations can automate email triage, helping to ensure that urgent issues receive immediate attention while routine inquiries are processed efficiently.
This article explores how enterprises can integrate these technologies to optimize help desk and other customer service operations.
The challenge: Manual email triage is inefficient
Traditional email triage relies on human agents to read, categorize, and prioritize emails. This approach is:
- Slow: A high volume of emails overwhelms human teams.
- Inconsistent: Different agents may classify the same email differently.
- Error-prone: Critical issues may be overlooked due to human oversight.
By automating email categorization and prioritization with AI, organizations can eliminate inefficiencies while maintaining accuracy.
The solution: AI-powered email classification
Customer emails to help desks generally fall into one of six categories:
- Requirement: Requests for new features or functionalities that do not yet exist.
- Enhancement: Suggestions to improve existing features or functionalities.
- Defect: Reports of system bugs, failures, or unexpected behavior.
- Security issues: Concerns related to security vulnerabilities, security breaches, or data loss or exposure.
- Feedback: General suggestions, both positive and negative, about the product.
- Configuration issues: Difficulties in setting up the system.
Using a text classification model trained on historical data, enterprises can automatically categorize incoming emails, reducing manual effort and improving efficiency.
Sentiment analysis : The priority filter
Beyond categorization, sentiment analysis detects the emotional tone of emails. Classifying the sentiment of emails as positive, neutral, or negative can help with prioritizing the responses.
Examples of sentiment analysis
- Positive sentiment: “I love this feature, but can we add X?”
- Route to Enhancement Team
- Tag as Low Priority
- Neutral sentiment: “I found a bug in the login system.”
- Route to Bug Fixing Team
- Tag as Medium Priority
- Negative sentiment: “Your app is terrible, login doesn’t work!”
- Route to Critical Defect Resolution Team
- Tag as High Priority
About the training data set
The data set used to train the model is a dummy data set that I created specifically for this project. It simulates real-world help desk email content and includes labeled examples across the six categories introduced above (Requirement, Enhancement, Defect, Security issue, Feedback, and Configuration issue). Each email is paired with a sentiment label (positive, neutral, or negative) to support both categorization and prioritization based on tone.
The data set has been uploaded to a public GitHub repository, and you can access it here.
Step 1: Import required libraries
Our implementation relies on Pandas for data manipulation, NLTK for natural language processing, including sentiment analysis via SentimentIntensityAnalyzer, and Scikit-learn for text classification, using the Multinomial Naive Bayes classifier.
import pandas as pd
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
from sklearn.naive_bayes import MultinomialNB
Step 2: Preprocess the training data
We preprocess the training data by removing special characters, eliminating stopwords like “and” and “the,” and applying lemmatization to reduce words to their base forms. These steps enhance data quality and improve the model’s performance.
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('vader_lexicon')
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
#object of WordNetLemmatizer
lm = WordNetLemmatizer()
def text_transformation(df_col):
corpus = []
for item in df_col:
new_item = re.sub('[^a-zA-Z]',' ',str(item))
new_item = new_item.lower()
new_item = new_item.split()
new_item = [lm.lemmatize(word) for word in new_item if word not in set(stopwords.words('english'))]
corpus.append(' '.join(str(x) for x in new_item))
return corpus
corpus = text_transformation(df_train['text'])
To convert the textual data to numerical data for machine learning, we use CountVectorizer from Scikit-learn.
cv = CountVectorizer(ngram_range=(1,2))
traindata = cv.fit_transform(corpus)
X = traindata
y = df_train.label
In the code snippet above, note that
CountVectorizer(ngram_range=(1, 2))converts the preprocessed email text (from corpus) into a matrix of token counts, including both unigrams (single words) and bigrams (pairs of words).Xis the feature matrix used to train the model.yis the target variable containing the email categories (Requirement, Enhancement, Defect, etc.).
Step 3: Train the classification model
We use the Multinomial Naïve Bayes model, a probabilistic algorithm ideal for text classification, to fit our training vectors to the values of the target variable.
classifier = MultinomialNB()
classifier.fit(X, y)
Why Multinomial Naïve Bayes?
The Multinomial Naïve Bayes model is particularly well-suited for text classification tasks where features are based on word counts or frequencies—exactly the case with our data set. Multinomial Naïve Bayes is a good match for our data for several reasons:
- Categorical data: Our data set consists of labeled email text, where the features (words and phrases) are naturally represented as discrete counts or frequencies.
- High-dimensional sparse features: The output from
CountVectorizerorTfidfVectorizercreates a large, sparse matrix of word occurrences. Multinomial Naïve Bayes handles this kind of input efficiently and effectively without overfitting. - Multi-class classification: We are categorizing emails into six distinct classes. Multinomial Naïve Bayes supports multi-class classification out of the box, making it a clean fit for this problem.
- Speed and efficiency: Multinomial Naïve Bayes is computationally lightweight and trains quickly, which is especially helpful when iterating on feature engineering or working with dummy data sets.
- Strong baseline performance: Even with minimal tuning, Multinomial Naïve Bayes tends to perform well on text classification tasks, giving us a strong, reliable baseline to compare other models against.
There are several other machine learning models including logistic regression, support vector machines, random forests/decision trees, and deep learning models such as LSTM and BERT that also perform well on text classification tasks. Multinomial Naïve Bayes is a good starting point due to its simplicity and effectiveness, but it’s generally a good practice to try multiple algorithms and compare their performance.
To compare the performance of different models, we use evaluation metrics such as
- Accuracy: The percentage of total predictions that were correct. Accuracy is highest when classes are balanced.
- Precision: Of all the emails the model labeled as a certain category, the percentage that were correct.
- Recall: Of all the emails that truly belong to a category, the percentage the model correctly identified.
- F1-score: The harmonic mean of precision and recall. F1 provides a balanced measure of performance, when you care about both false positives and false negatives.
- Support: Indicates how many actual samples there were for each class. Support is helpful in understanding class distribution.
Step 4: Test the classification model and evaluate performance
The code listing below combines a number of steps—preprocessing the test data, predicting the target values from the test data, and evaluating the model’s performance by plotting the confusion matrix and computing accuracy, precision, and recall. The confusion matrix compares the model’s predictions with the actual labels. The classification report summarizes the evaluation metrics for each class.
#Reading Test Data
test_df = pd.read_csv(test_Data.txt',delimiter=';',names=['text','label'])
# Applying same transformation as on Train Data
X_test,y_test = test_df.text,test_df.label
#pre-processing of text
test_corpus = text_transformation(X_test)
#convert text data into vectors
testdata = cv.transform(test_corpus)
#predict the target
predictions = clf.predict(testdata)
#evaluating model performance parameters
mlp.rcParams['figure.figsize'] = 10,5
plot_confusion_matrix(y_test,predictions)
print('Accuracy_score: ', accuracy_score(y_test,predictions))
print('Precision_score: ', precision_score(y_test,predictions,average='micro'))
print('Recall_score: ', recall_score(y_test,predictions,average='micro'))
print(classification_report(y_test,predictions))
Output –
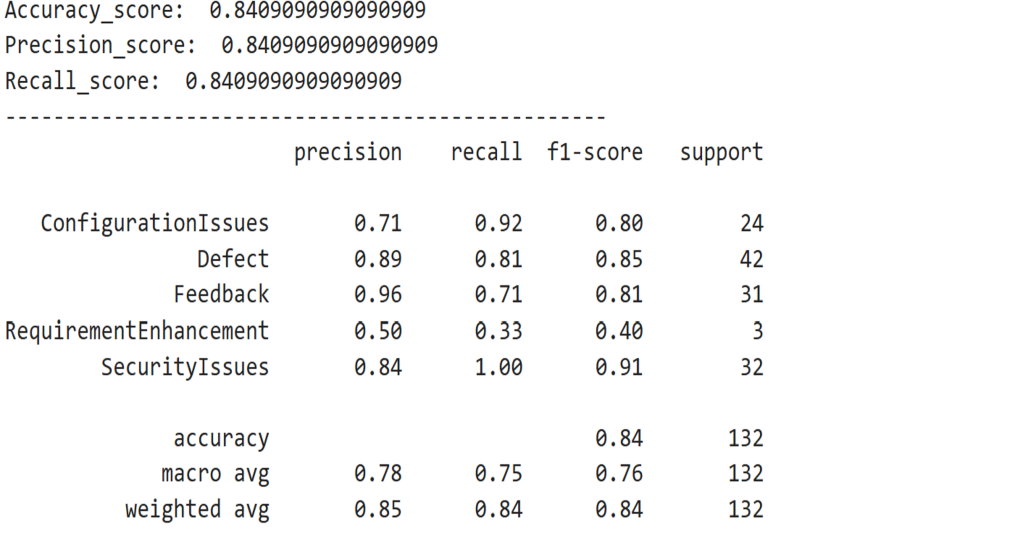
IDG
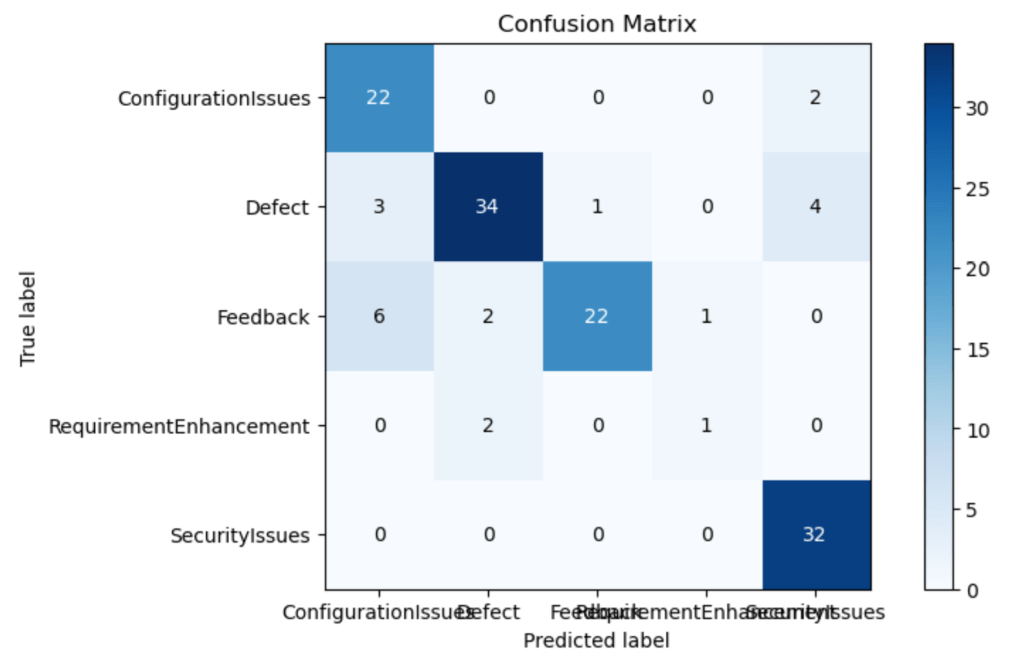
IDG
While acceptable thresholds vary depending on the use case, a macro-average F1-score above 0.80 is generally considered good for multi-class text classification. The model’s F1-score of 0.8409 indicates that the model is performing reliably across all six email categories.
Rules of thumb
- If accuracy and F1-score are both above 0.80, the model is typically considered production-ready in many business scenarios.
- If recall is low, the model may be missing important cases—critical for high-priority email triage.
- If precision is low, the model may be flagging incorrect emails—problematic for sensitive categories like Security Issues.
Step 5: Integrate sentiment analysis
We integrate NLTK’s SentimentIntensityAnalyzer to score emails by sentiment intensity. We set priority to high for negative sentiment, to medium for neutral sentiment, and to low for positive sentiment.
sia = SentimentIntensityAnalyzer()
def get_sentiment(text):
# Predict Category (Ensure it is a string)
category = clf.predict(cv.transform([text]))[0] # Extract first element
# Sentiment Analysis
sentiment_score = sia.polarity_scores(text)['compound']
if sentiment_score >= 0.05:
sentiment = "Positive"
elif sentiment_score
Step 6: Test the complete model
Example 1
email_sentiments = get_sentiment('Your app is terrible and not secure, login doesn’t work!')
print(email_sentiments)
Output -
{ 'Category': 'SecurityIssues', 'Sentiment': 'Negative','Priority': 'High'}
Example 2
email_sentiments = get_sentiment('Add advanced filtering and export options for reports')
print(email_sentiments)
Output -
{
'Category': 'RequirementEnhancement','Sentiment': 'Positive','Priority': 'Low'
}
Here is the GitHub repository link for the whole code.
Combining classification and sentiment analysis
Combining machine learning-based classification and sentiment analysis creates a robust AI-powered email triage system. This approach helps enterprises scale their customer support operations while maintaining efficiency, reducing response times, and ensuring high-impact issues receive immediate attention. As organizations handle increasing digital communication, such solutions become essential to delivering superior customer service while optimizing operational costs.
{kind=link}
Why LLM applications need better memory management 6 May 2025, 11:00 am
You delete a dependency. ChatGPT acknowledges it. Five responses later, it hallucinates that same deprecated library into your code. You correct it again—it nods, apologizes—and does it once more.
This isn’t just an annoying bug. It’s a symptom of a deeper problem: LLM applications don’t know what to forget.
Developers assume generative AI-powered tools are improving dynamically—learning from mistakes, refining their knowledge, adapting. But that’s not how it works. Large language models (LLMs) are stateless by design. Each request is processed in isolation unless an external system supplies prior context.
That means “memory” isn’t actually built into the model—it’s layered on top, often imperfectly. If you’ve used ChatGPT for any length of time, you’ve probably noticed:
- It remembers some things between sessions but forgets others entirely.
- It fixates on outdated assumptions, even after you’ve corrected it multiple times.
- It sometimes “forgets” within a session, dropping key details.
These aren’t failures of the model—they’re failures of memory management.
How memory works in LLM applications
LLMs don’t have persistent memory. What feels like “memory” is actually context reconstruction, where relevant history is manually reloaded into each request. In practice, an application like ChatGPT layers multiple memory components on top of the core model:
- Context window: Each session retains a rolling buffer of past messages. GPT-4o supports up to 128K tokens, while other models have their own limits (e.g. Claude supports 200K tokens).
- Long-term memory: Some high-level details persist across sessions, but retention is inconsistent.
- System messages: Invisible prompts shape the model’s responses. Long-term memory is often passed into a session this way.
- Execution context: Temporary state, such as Python variables, exists only until the session resets.
Without external memory scaffolding, LLM applications remain stateless. Every API call is independent, meaning prior interactions must be explicitly reloaded for continuity.
Why LLMs are stateless by default
In API-based LLM integrations, models don’t retain any memory between requests. Unless you manually pass prior messages, each prompt is interpreted in isolation. Here’s a simple example of an API call to OpenAI’s GPT-4o:
import { OpenAI } from "openai";
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{ role: "system", content: "You are an expert Python developer helping the user debug." },
{ role: "user", content: "Why is my function throwing a TypeError?" },
{ role: "assistant", content: "Can you share the error message and your function code?" },
{ role: "user", content: "Sure, here it is..." },
],
});
Each request must explicitly include past messages if context continuity is required. If the conversation history grows too long, you must design a memory system to manage it—or risk responses that truncate key details or cling to outdated context.
This is why memory in LLM applications often feels inconsistent. If past context isn’t reconstructed properly, the model will either cling to irrelevant details or lose critical information.
When LLM applications won’t let go
Some LLM applications have the opposite problem—not forgetting too much, but remembering the wrong things. Have you ever told ChatGPT to “ignore that last part,” only for it to bring it up later anyway? That’s what I call “traumatic memory”—when an LLM stubbornly holds onto outdated or irrelevant details, actively degrading its usefulness.
For example, I once tested a Python library for a project, found it wasn’t useful, and told ChatGPT I had removed it. It acknowledged this—then continued suggesting code snippets using that same deprecated library. This isn’t an AI hallucination issue. It’s bad memory retrieval.
Anthropic’s Claude, which offers prompt caching and persistent memory, moves in the right direction. Claude allows developers to pass in cached prompt fragments using pre-validated identifiers for efficiency—reducing repetition across requests and making session structure more explicit.
But while caching improves continuity, it still leaves the broader challenge unsolved: Applications must manage what to keep active in working memory, what to demote to long-term storage, and what to discard entirely. Claude’s tools help, but they’re only part of the control system developers need to build.
The real challenge isn’t just adding memory—it’s designing better forgetting.
Smarter memory requires better forgetting
Human memory isn’t just about remembering—it’s selective. We filter details based on relevance, moving the right information into working memory while discarding noise. LLM applications lack this ability unless we explicitly design for it. Right now, memory systems for LLMs fall into two flawed categories:
- Stateless AI: Completely forgets past interactions unless manually reloaded.
- Memory-augmented AI: Retains some information but prunes the wrong details with no concept of priority.
To build better LLM memory, applications need:
- Contextual working memory: Actively managed session context with message summarization and selective recall to prevent token overflow.
- Persistent memory systems: Long-term storage that retrieves based on relevance, not raw transcripts. Many teams use vector-based search (e.g., semantic similarity on past messages), but relevance filtering is still weak.
- Attentional memory controls: A system that prioritizes useful information while fading outdated details. Without this, models will either cling to old data or forget essential corrections.
Example: A coding assistant should stop suggesting deprecated dependencies after multiple corrections.
Current AI tools fail at this because they either:
- Forget everything, forcing users to re-provide context, or
- Retain too much, surfacing irrelevant or outdated information.
The missing piece isn’t bigger memory—it’s smarter forgetting.
GenAI memory must get smarter, not bigger
Simply increasing context window sizes won’t fix the memory problem. LLM applications need:
- Selective retention: Store only high-relevance knowledge, not entire transcripts.
- Attentional retrieval: Prioritize important details while fading old, irrelevant ones.
- Forgetting mechanisms: Outdated or low-value details should decay over time.
The next generation of AI tools won’t be the ones that remember everything. They’ll be the ones that know what to forget. Developers building LLM applications should start by shaping working memory. Design for relevance at the contextual layer, even if persistent memory expands over time.
{kind=link}
Public clouds burnish their on-premises options 6 May 2025, 11:00 am
One of the more notable developments in enterprise IT was public cloud providers offering on-premises services. These appear to be regaining steam, as Amazon Web Services recently unveiled second-generation AWS Outposts racks packed with cutting-edge hardware, such as fourth-generation Intel Xeon Scalable processors, to boost performance for on-premises workloads.
AWS has also introduced specialized instance types, such as bmn-sf2e, for latency-sensitive, compute-intensive, and throughput-oriented applications such as real-time data distribution, risk analytics, and 5G core networks. These upgrades reflect a growing reality: The public cloud can’t meet every need, and enterprises are shifting resources toward hybrid cloud and on-prem models to address evolving requirements.
Is it likely that more public cloud providers will follow suit? At the core, this is about staying in step with multiplatform enterprise strategies and preparing for the next decade of AI-accelerated workloads. The world of enterprise IT is changing quickly, and cloud providers want to ensure their relevance in this new era.
The need for diverse platforms
Enterprises’ multiplatform workload strategies will continue to drive the rise of on-prem offerings by public cloud players. Increasingly, organizations are choosing to deploy workloads across various platforms—public cloud, private cloud, and on-premises. This diversification reflects the need for flexibility, cost-efficiency, and control.
On-prem solutions can help enterprises prioritize cost predictability and performance optimization. With pay-as-you-go pricing models and premium costs for cutting-edge hardware, public clouds are proving too expensive for many organizations. This has opened the door for other models, such as on-premises or hybrid cloud, which give enterprises more predictable and, in many cases, lower operating costs.
AWS’s new Outposts racks are a good example of cloud providers aligning with these trends. Organizations can leverage AWS’s infrastructure and tools in their data centers while benefiting from improved compute, memory, and network capacity tailored to mission-critical workloads. The flexibility to independently scale computing and networking resources is another key advantage, reducing the need to buy entire racks and allowing for more strategic scaling without unnecessary overhead.
Hybrid and on-prem suit an AI-driven future
One of the most significant reasons for the growth of hybrid and on-prem solutions is the looming challenge of generative AI workloads. Within the next decade, enterprises are expected to heavily invest in AI systems, both for training models and for deploying real-time inferencing applications. These workloads are resource-hungry, and their cost has proven to be a substantial barrier to growth. Public clouds aren’t cost-competitive for enterprises needing consistent, long-term access to large amounts of compute and storage power.
By bringing AI operations to on-premises environments or hybrid models, enterprises can better predict and manage expenses, minimize latency, and remain in full control of their data. These models also allow organizations to focus on the long term instead of being at the mercy of cloud pricing dynamics, which can change unpredictably. Additionally, hybrid cloud models position enterprises for the next wave of AI innovation. AI is a rapidly evolving space where agility is a must. Enterprises that invest in versatile architectures across cloud and on-prem data centers will have the flexibility to scale and pivot their operations as the technology matures.
Are public clouds pricing themselves out?
It’s easy to see why the shift to hybrid and on-prem models is happening, but it’s equally important to consider why public clouds are losing ground. Much of this can be attributed to pricing for the most resource-intensive workloads. Massive parallel processing and specialized accelerators quickly become cost-prohibitive in many public cloud environments.
The new AWS instance types indicate that public clouds recognize this problem and are attempting to address it by offering tailored solutions for on-prem environments. However, this is more of an exception than a rule, so far. Public clouds remain heavily invested in premium pricing models for their centralized services, which won’t work for enterprises looking to scale AI operations at a reasonable price point.
The path forward
Strategic decisions must support scalability, cost-efficiency, and innovation in an AI-driven future. Simply put, enterprises need to take control of their infrastructure decisions rather than being wholly reliant on public cloud services.
First, organizations must deeply analyze their workloads. Developing a clear understanding of where to place each workload—public cloud, on-prem, or hybrid cloud model—is essential. AI workloads, in particular, should be examined through the lens of performance needs, latency requirements, and long-term cost implications. The public cloud might be ideal for development and initial testing, but long-term operations will often benefit from more cost-effective on-premises solutions.
Second, enterprises need to build flexibility into their architectures. By investing in hybrid cloud infrastructure, businesses can leverage the best of both worlds: the scalability of public cloud and the control of on-prem environments. This means considering vendors such as AWS, which offer compelling hybrid and on-prem options, but also keeping an eye on emerging players and alternatives that may offer better pricing or specialized solutions.
Finally, sustainability and future-proofing must be core parts of the equation. AI workloads will become essential to business strategy, and the cost will continue to climb. Enterprises must adopt approaches that are not just cost-efficient now but that help set the stage for AI-driven growth in the next 10 years. Choosing platforms that balance innovation and cost will ensure stability in a market that is constantly changing.
{kind=link}
JetBrains open-sources Mellum LLM 5 May 2025, 6:09 pm
JetBrains has open-sourced its Mellum large language model (LLM), which was purpose-built for code completion, with the aim to grow Mellum into a family of models specialized for different coding tasks.
The Mellum base model was open-sourced and made available on Hugging Face on April 30. By releasing Mellum on Hugging Face, JetBrains is offering researchers, educators, and advanced teams the opportunity to explore how a purpose-built model works under the hood, JetBrains said. The company trained Mellum to power cloud-based code completion in JetBrains IDEs. However, Mellum is not aimed at the average developer, but is best suited for AI and machine learning researchers, engineers, and educators who want to explore, fine-tune, or teach domain-specific LLMs in the context of software development.
Mellum is being open-sourced because JetBrains believes in transparency, collaboration, and the power of shared progress, JetBrains said. Open source has driven big leaps in technology in areas such as Linux, Git, Node.js, and Docker, and now open source LLMs are outperforming some proprietary industry leaders, according to JetBrains. Released to the public last year, Mellum supports code completion for languages including Java, Kotlin, Python, Go, PHP, C, C++, C#, JavaScript, TypeScript, CSS, HTML, Rust, and Ruby.
{kind=link}
How MCP could add value to MongoDB databases 5 May 2025, 1:59 pm
MongoDB has added Anthropic’s Model Context Protocol (MCP) to all its databases, including Atlas, to help developers accelerate software development and manage database administrative tasks.
MCP, which has seen a rise in popularity since its release in November last year, is an open protocol that allows AI agents inside applications to access external tools and data to complete a user request using a client-server mechanism, where the client is the AI agent or agentic interface and the server provides tools and data.
The rise in MCP’s popularity can be attributed, in turn, to the proliferation of agentic applications that can perform tasks without manual intervention, allowing enterprises and their teams to do more with limited resources.
However, in order to make any application agentic, developers need to make use of a protocol, such as MCP, to connect it to a large language models (LLMs) for reasoning as well as provide necessary data for context, and tools to complete a user request without manual intervention.
Managing database administrative tasks via MCP clients
In MongoDB’s case, developers can make use of the MongoDB MCP Server, which is currently in public preview, to integrate MCP-supported clients, such as Windsurf, Cursor, GitHub Copilot in VS Code, and Anthropic Claude, to its databases — Atlas, MongoDB Community Edition, and MongoDB Enterprise Advanced.
Post integration, developers would be able to use these MCP-supported clients to explore data inside databases or query data for analytics in natural language, the company wrote.
Additionally, developers would also be able to use these clients to perform database administration tasks, such as creating a new database user with read-only access or listing the current network access rules, in natural language.
These capabilities, according to Benjamin Flast, director of Product Management at MongoDB, free developers from undifferentiated tasks like manual query optimization and database administration, thereby increasing productivity, which results in accelerated application development.
Moor Insights & Strategy Principal Analyst Jason Andersen said that most database vendors are likely to adopt MCP, just like they have retrieval augmented generation (RAG) for providing context to LLMs.
MongoDB isn’t the only database provider that has added support for MCP. Several databases, such as PostgreSQL and SQL, already support the protocol via Azure Database for PostgreSQL MCP Server, PG-MCP, and MySQL MCP Server, respectively.
Google recently announced support for MCP integration for databases through its GenAI Toolbox for Databases. It also renamed its GenAI Toolbox for Databases to MCP Toolbox for Databases.
Data management and analytics platform providers, according to The Futurum Group’s lead for data and analytics practice, Bradley Shimmin, are in the process of developing their own MCP implementations and blending those into their individual user workflows
“Data integrator and API manager Boomi, for example, is setting up its own MCP gateway to marshal and manage MCP requests from across many disparate MCP servers,” Shimmin said.
Context-aware vibe coding via MCP clients
Another advantage of MongoDB integrating MCP with its databases is to help developers code faster, Flast said, adding that the integration will help in context-aware code generation via natural language in MCP supported coding assistants, such as Windsurf, Cursor, and Claude Desktop.
“Providing context, such as schemas and data structures, enables more accurate code generation, reducing hallucinations and enhancing agent capabilities,” MongoDB explained in the blog, adding that developers can describe the data they need and the coding assistant can generate the MongoDB query along with application code that is needed to interact with it.
MongoDB’s efforts to introduce context-aware vibe coding via MCP clients, according to Andersen, will help enterprises reduce costs, both financial and technical debt, and sustain integrations with AI infrastructure.
However, Shimmin pointed out that MCP integration with databases will usher in a trend where two modes of development practices — Direct API access via SDKs and MCP integration — will co-mingle.
“Direct API access will deliver the best performance and control for highly programmatic interactions. For more flexible interactions, where LLMs might stand in for software developers, writing their own, ‘soft’ APIs on the fly, enterprises will rely upon standard resource documentation like MCP to guide those models in accessing those resources,” Shimmin said.
Security issues around MCP
According to Matt Aslett, director at ISG Software Research, MCP has a host of security issues, especially around access control, although the analyst expects to see solutions to these challenges from the developer community due to the protocol’s proliferation.
Andersen pointed out that developers and enterprises, with support from vendors, in general, are deploying MCP within a cloud to bypass access control issues as cloud has a common authentication and authorization infrastructure.
“This helps ensure that the right resources are allowed to talk to each other. So, when deployed in a homogeneous environment, you are trusting what is already in place,” Andersen said, adding that some enterprises or developers might feel the cloud workaround as “not good enough”.
Similarly, Shimmin pointed out that securing MCP will be up to the database vendors themselves, as they have to ensure that they are not opening up access to data without some means of controlling that access.
{kind=link}
Bringing DevOps, DevSecOps, and MLOps together 5 May 2025, 11:00 am
There are many moving parts in software development, particularly as tech and the role of engineers quickly evolve. Against this backdrop, there is transformative potential for “EveryOps” in 2025.
But what exactly is EveryOps? We coined the term to include DevOps, DevSecOps, MLOps, and any other additional Ops on the way. Here, we will examine how EveryOps will redefine the software development process while addressing current limitations and future needs.
The current state of software development
When discussing the operational aspects of this market, it becomes clear that software development is highly nonlinear. In the application development tools space, for example, there is a progression from basic applications to more advanced applications. The trend of applications becoming more complex is also impacted by the incorporation of AI into the newly developed software. This pattern is familiar from earlier shifts, like those seen with client-server models and cloud computing.
However, a third area of focus that includes elements like observability and CI/CD (continuous integration and continuous delivery) is particularly interesting. Many startups in this space have matured into later phases of their life cycle, and while some businesses maintain a clean, linear, supply-chain-like approach, larger enterprises in the domain may apply a different strategy. These companies often acquire various tools and technologies, leading to overlapping and sometimes conflicting components that they must integrate and reconcile.
This has raised questions about whether the operational space is collapsing. In reality, rather than consolidating neatly, the market remains highly fragmented. There is still a significant need to educate the industry on how new tools work, and new startups continue to emerge.
It’s a wild, fragmented space that presents both challenges and opportunities, and an EveryOps philosophy is a way organizations can make sense of it all.
EveryOps: Building trusted software
The concept behind EveryOps is centered around building trusted software. To achieve this, we advocate for a model resembling a traditional factory, complete with a supply chain—in this case, the software supply chain. At the end of the day, the goal for organizations is to operate a trusted software factory. They need to be able to inspect and prove the secure output of software components to various stakeholders such as compliance managers, CISOs, CIOs, and even external auditors. Sometimes, it’s simply about adhering to internal organizational policies to deliver software to customers, whether for a device or a service.
With this in mind, it doesn’t matter what components are included in the software you create or what runtime environment you ultimately deploy to. Some domains, like IoT, are still developing but will mature. For instance, we’ve had initial discussions about software in electric vehicles, and we anticipate these developments will extend even to remote or peripheral devices. This shift from servers to edge devices is inevitable. We also see this vision unfolding in areas like machine learning.
The core message of EveryOps is that a secure software factory must encompass everything. Automation is essential. Software pipelines must include robust policies to ensure trustworthiness. Ultimately, you must maintain control and demonstrate trust in the entire process.
For me, the secret sauce lies in building a system that is highly opinionated in its foundational concepts but remains open and API-driven. This approach allows organizations to gradually adopt and integrate different aspects of the software supply chain while ensuring security and reliability throughout.
Why EveryOps is imperative
There’s been a clear shift in software development towards developers owning applications end-to-end across the software development life cycle (SDLC), from coding and deployment to security and maintenance. The adoption of cloud platforms drove this trend, which aims to accelerate the delivery of secure, high-quality applications.
This DevSecOps approach shines by enhancing developer productivity and fostering collaboration within organizations that embrace DevOps principles. By baking security practices into every stage of the SDLC, DevSecOps reduces vulnerabilities and puts teams in a position to deliver high-quality software at an accelerated pace. Fast forward to today, and software development has evolved to incorporate increasingly complex dependencies, with new challenges emerging. This is especially true with the growing influence of machine learning, AI, and generative AI technologies.
AI and machine learning are no longer standalone initiatives limited to data science teams. They are becoming deeply embedded into modern software systems, making integrating MLOps into the broader DevOps and DevSecOps ecosystems necessary. Traditionally, MLOps practices operated in silos and focused on the needs of data scientists and engineers. As the boundaries between DevOps, DevSecOps, and MLOps blur, organizations need a more unified approach to effectively manage the complexities of all three domains.
This is why the EveryOps philosophy is vital in the modern age of software development.
Bridging gaps and building unity with EveryOps
Embracing EveryOps is a paradigm shift emphasizing the importance of bridging the technical gaps and cultural divides between DevOps, DevSecOps, and MLOps teams. It’s a holistic, inclusive approach to software and machine learning development, where ops teams are responsible for all domains across a unified EveryOps software supply chain and development pipeline. It’s all about creating a culture of end-to-end responsibility and continuous improvement so teams can maintain velocity without compromising trust or quality.
A core principle of EveryOps is seamlessly integrating trust and accountability into the SDLC with minimal friction for developers. This means security must be incorporated into the process and streamlined to avoid unnecessary bottlenecks. Developers, data scientists, and engineers must leverage tools and processes that empower them to work efficiently while adhering to best practices.
This sounds enticing, but what does it take in practice? At a high level, making EveryOps a reality means leveraging tools and frameworks designed for cross-collaboration between traditionally siloed teams. As we know, data scientists and engineers bring unique skills and requirements to the table, with functions including model training, data preprocessing, performance optimization, and more. Meanwhile, developers tend to prioritize aspects like CI/CD pipelines, infrastructure as code, and application scalability.
The convergence of these varied roles requires applying sound engineering principles to MLOps to ensure transparent management of a fully automated machine learning life cycle—from data preparation to model deployment and monitoring. Like traditional DevOps or DevSecOps workflows before it, centralized management of machine learning workflows and artifacts is critical for creating a unified view everyone can rely on.
Benefits of adopting EveryOps for machine learning
By embracing EveryOps, organizations can expect several key benefits, including:
- Enhanced trust: A consolidated visibility for machine learning workflows and artifacts allows stakeholders to quickly and confidently rely on the outputs of AI systems, knowing they’ve been developed and deployed with accountability.
- Improved efficiency: Streamlined, automated processes and shared tools minimize team friction, enabling faster cycles and more effective collaboration.
- Scalability and resilience: Unified EveryOps practices ensure that software and machine learning systems can scale effectively while maintaining top-level security and reliability.
- Cultural alignment: Breaking down silos creates a culture of end-to-end responsibility and continuous learning, which drives innovation and long-term success.
The EveryOps philosophy isn’t just a strategy for integrating DevOps, DevSecOps, and MLOps—it’s a call to action for organizations to embrace a unified, collaborative mindset that transcends technical and cultural barriers. As adoption of AI and machine learning continues to rise, EveryOps will be critical in ensuring organizations remain agile, secure, and competitive in an increasingly complex landscape.
The EveryOps philosophy is already redefining software development. By uniting DevOps, DevSecOps, MLOps, and emerging Ops under a cohesive framework, organizations give themselves a better chance at addressing the complexities of modern software and new machine learning workflows. Further, prioritizing trust, visibility, and automated controls across the software supply chain ensures teams can deliver secure, reliable, and scalable solutions.
Adopting EveryOps is not just an option—it’s imperative for staying competitive. Bridging gaps, fostering cultural alignment, and enabling speed and productivity empower organizations to thrive.
Yoav Landman is co-founder and CTO of JFrog.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
{kind=link}
Knowing when to use AI coding assistants 5 May 2025, 11:00 am
Just because you can use generative AI in software development doesn’t mean you should. AI coding assistants powered by large language models (LLMs) are a productivity dream in some cases but a debugging nightmare in others. So, where is that line?
“Knowing when and how to rely on AI code assistants is an important skill to learn,” says Kevin Swiber, API strategist at Layered System. “It’s changing day by day as the technology advances. It’s hard to keep up.”
63% of professional developers currently use AI within their development process, according to Stack Overflow’s 2024 Developer Survey. AI coding assistants are proving to be an incredible time saver for boilerplate code, simple functions, documentation, and debugging.
However, AI-generated code is riddled with quality concerns, and a heavy reliance on it compounds technical debt. Experts view AI agents as less ideal for completely novel coding projects, highly complex architectures, long build cycles, or code reuse.
The short and skinny? AI works better in some situations than others. (Not to harsh your vibe, but vibe coding still requires human supervision.) Below, we’ll consider when AI tools shine and when they don’t, and offer some takeaways for software engineering leaders.
Where AI coding assistants shine
AI performs exceptionally well with common coding patterns. Its sweet spot is generating new code with low complexity when your objectives are well-specified and you’re using popular libraries, says Swiber.
“Web development, mobile development, and relatively boring back-end development are usually fairly straightforward,” adds Charity Majors, co-founder and CTO of Honeycomb. The more common the code and the more online examples, the better AI models perform.
Quicker feedback cycles with AI tend to lead to a better experience. “Tasks with quick feedback loops, like front-end development or writing unit tests, tend to work particularly well,” says Majors. “If it takes you two hours to deploy your back-end code, this will be more challenging.”
Harry Wang, chief growth officer at Sonar, says AI excels at well-understood programming tasks like scaffolding microservices, generating REST APIs, or prototyping new ideas.
“AI coding assistants truly shine when they augment developers, taking on routine and repetitive tasks like generating boilerplate code or suggesting code snippets, functions, or even entire classes,” Wang says. “They accelerate rapid prototyping, exploratory design, and experimental coding, turning initial ideas into tangible code much faster.”
Then, there are all the practical tasks AI can achieve for developers outside the actual code. Spencer Kimball, CEO of Cockroach Labs, describes how their engineers often use AI for design scaffolding, fixing tests, observability data, and blogging. 70% of the time, that’s not direct coding, but it’s giving back more time to developers to program, he says.
Where AI coding assistants fall short
In other situations, you may struggle to get AI working. Generative AI tools can falter when engineering goals go beyond a one-off function, aren’t well-specified, involve large-scale refactoring, or span entirely novel projects with complex requirements.
“You can waste a lot of time and money—and literally lose code—if you just let it do its own thing,” says Layered System’s Swiber. This risk grows if you’re not reviewing outputs regularly or using version control.
Honeycomb’s Charity mostly agrees: “AI is much better at generating greenfield code than it is at modifying or extending an existing code base.” Exceptions include large language models trained on that precise task, she adds.
While AI accelerates development, it creates a new burden to review and validate the resulting code. “In a worst-case scenario, the time and effort required to debug and fix subtle issues in AI-generated code could even eclipse the time it would require to write the code from scratch,” says Sonar’s Wang.
Quality and security can suffer from vague prompts or poor contextual understanding, especially in large, complex code bases. Transformer-based models also face limitations with token windows, making it harder to grasp projects with many parts or domain-specific constraints.
“We’ve seen cases where AI outputs are syntactically correct but contain logical errors or subtle bugs,” Wang notes. These mistakes originate from a “black box” process, he says, making AI risky for mission-critical enterprise applications that require strict governance.
“Early-stage projects benefit from AI’s flexibility, while mature code bases demand caution due to risks of context loss and integration conflicts,” says Wang. Part of this is a lack of access to the proper context and data for the use case at hand.
Although Cockroach Labs’ Kimball acknowledges that AI coding tools are improving, the complexity of Cockroach’s massive code base still poses challenges for AI assistants. “There’s way too much context,” he says. Instead of attempting to load everything, he explains how you can stay productive by narrowing your focus to local context and related interfaces. “You want to understand the things that are attached to the one file you’re looking at, and black box some of those things.”
By treating parts of the system as abstractions, developers can work iteratively within a smaller scope—a mindset Kimball says helps developers stay productive, even in complex systems like Cockroach’s.
What engineering leaders should know
“It’s no accident everyone’s interested in AI, because it’s a paradigm shift on the same level of electrification or computerization,” adds Kimball, who recently experimented hands-on with vibe coding using Model Context Protocol (MCP) servers wrapped around Cockroach’s APIs.
“As a CEO, it gives you a bit of perspective on what’s possible,” Kimball says. “If you can get a 30% boost in productivity, it’s like hiring 30 people.” Although overspending on AI is a valid concern, the cost pales in comparison to hiring additional engineers, he says.
In fact, AI can give companies an edge. “Don’t worry about spending in the short term—figure out how to use this stuff,” says Kimball. “It’s much better to be a 500-person company than a 5,000-person company.” To his point, new research from DX found that mid-size companies had the highest revenue per engineer compared to other company sizes.
Executives are hot on AI at the moment. Shopify’s CEO’s AI mandate is anticipated to usher in similar decrees and affect hiring. But while AI fervor mounts, the onus is on leaders to understand the limitations of AI and begin delineating boundaries.
Deploying AI willy-nilly can quickly lead to frustrating outcomes—like a model getting itself stuck in a recursive loop of failed tests, says Swiber. “You can’t just set these things off and let them go. You need to monitor what they’re doing.”
Leaders can’t afford to sit on their laurels, either. The fact is, developers will use generative AI regardless of whether they have approval yet. 64% of software developers who use generative AI began using the technology before they were officially granted licenses to do so, according to a 2024 report from BlueOptima.
Both developers and leadership should gain familiarity with AI coding assistants to understand their strengths and weaknesses. This awareness will be critical to rolling them out effectively.
The worst the models will ever be
The challenge is that, given the rapid pace of change, AI discussions often become irrelevant in a few short months… or even weeks. “AI coding assistants are changing rapidly, so anything we say about them probably has a short shelf life,” says Majors.
The future capabilities of AI are hard to forecast. But more and more developers are bullish on its role in their day-to-day workflows and big picture goals. Salesforce’s latest State of IT survey found that 92% of developers expect agentic AI to advance their careers.
For Kimball, agentic AI will open countless doors and pose new threat vectors. “We’re gonna start going from billions to tens of billions to hundreds of billions, maybe even trillions of active things out there that are ultimately hitting APIs more than ever.”
At the enterprise level, the industry must start considering data sovereignty, he adds, because regional data restrictions are rising and agentic AI will lower the threshold for data access. Ultimately, data providers will have to satisfy these regulations and learn how to appropriately secure their data.
Context window limits—the amount of text that a model can consider at once—are what’s really holding back LLMs, but they’re constantly improving. What happens when context windows reach millions or hundreds of millions of tokens? Many of the issues surrounding AI in large code bases could evaporate.
As it stands now, issues still present themselves when working with LLMs for different coding tasks, requiring keen insight on when (and how) to use them wisely. Yet, as Kimball reminds us, AI coding tools are improving exponentially, and we’re only at the beginning.
“The future of software is AI,” he says. “This is the worst the models are ever going to be.”
{kind=link}
Deno 2.3 adds compile improvements, support for local NPM packages 4 May 2025, 6:50 pm
Deno Land has released Deno 2.3, an update of the company’s JavaScript and TypeScript runtime that brings improvements to deno compile and adds support for local NPM packages.
Announced May 1, Demo 2.3 extends deno compile to support programs that use Foreign Function Interface (FFI) and Node native add-ons. This means compiled binaries can include and work with native libraries or Node plug-ins. Also, deno compile now can exclude specific files from being embedded during the compilation process. This offers more control over which files get packaged into a standalone executable. With deno compile, developers can compile a project into a single binary, allowing them to distribute ready-to-run programs without having to install Deno or dependencies.
Deno 2.3 also introduces a Deno.build.standalone boolean to indicate if the code is running in a self-contained compiled binary. This can be useful for error reporting, feature toggling, user messaging, and more, in build-specific environments, according to Deno Land.
Deno 2.3 adds support for using local NPM packages, making testing and developing an NPM package locally possible. To use local NPM modules, developers need a local node_modules folder, which can be achieved with either "nodeModulesDir": "auto" or "nodeModulesDir": "manual". The "manual" option requires running deno install each time the local npm package is updated.
Installation instructions for Deno can be found at docs.deno.com. To upgrade to Deno 2.3, developers can run the following in their terminal: deno upgrade.
Other features in Deno 2.3 include the following:
- Improvements to
deno fmtallow developers to format embedded CSS, HTML, and SQL in tagged templates. - A new way is provided to install packages from NPM and JSR with the addition of registry flags
--npmand--jsr, respectively. - OpenTelemetry support has been expanded with basic event recording, span context propagators,
node:httpauto-instrumentation, and V8 JS engine metrics. - The
denoexecutable now is signed on Windows, making Microsoft Defender trust Deno. - Installing dependencies with
deno installanddeno addnow are about two times faster in most situations wherenpmdependencies have been cached. - Deno 2.3 improves on the Visual Studio Code Jupyter experience by ensuring that variables, modules, and type definitions are shared between Jupyter cells.
- Deno 2.3 upgrades to TypeScript 5.8 and V8 13.5 offer new language features and performance.
{kind=link}
AWS changes the pricing of CloudWatch logs in Lambda 2 May 2025, 3:06 pm
AWS has changed the pricing of CloudWatch logs inside its serverless compute service Lambda to introduce tiered pricing that can lower costs for high-volume enterprise users.
“On May 1st, 2025, AWS announced changes to Lambda logging, which can reduce Lambda CloudWatch logging costs and make it easier and more cost-effective to use a wider range of monitoring tools,” the company wrote in a blog post.
CloudWatch is an AWS service that allows enterprise developers to monitor, store, and access their log files from different AWS compute, networking, and storage services.
In Lambda’s case, logs generated from a Lambda instance, which are ingested by CloudWatch, can provide data and insights to developers to help them understand performance issues and potential failures of serverless applications and carry out actions such as troubleshooting and debugging.
“It becomes even more important for serverless applications built using Lambda because of the ephemeral and stateless nature of the Lambda execution environment,” the company wrote.
AWS offers three classes of logs under CloudWatch logs — Standard, Infrequent Access, and CloudWatch Logs Live Tail.
As part of the pricing change, AWS has renamed the Standard log class to Vended logs, and in contrast to the previously charged flat rate for this class, a new tiered pricing plan, based on volume, has been introduced.
Earlier, enterprises needed to pay a flat fee of $0.50 per GB for Standard logs ingestion on CloudWatch logs.
However, with the new volume-based tiered plan, enterprises will pay $0.50 per GB for the first 10 TB per month, $0.25 per GB for the next 20TB per month, $0.10 per GB for the next 20 TB per month, and $0.05 per GB for the next 50 TB per month.
“The pricing tiers scale with your logging volume, ensuring that cost benefits increase as your application grows. This allows you to maintain comprehensive logging practices that previously may have been cost-prohibitive,” AWS wrote.
The update also saw AWS change the pricing of the Infrequent Access log class, which is nearly 50% cheaper than the Standard log class.
In contrast to the flat fee of $0.25 per GB, enterprises will now pay $0.25 per GB for the first 10 TB per month, $0.15 per GB for the next 20TB per month, $0.075 per GB for the next 20 TB per month, and $0.05 per GB for the next 50 TB per month.
CloudWatch Logs Live Tail, which is an interactive, real-time log streaming and analytics capability, has undergone no pricing changes.
New places to store Lambda logs
In addition to changing the pricing of logs for Lambda, developers can also now store logs generated from their Lambda instances inside Amazon S3 and Amazon Data Firehose.
Both destinations also include a volume-based tiered pricing that is identical.
Enterprises have to pay $0.25 per GB for the first 10 TB per month, $0.15 per GB for the next 20TB per month, $0.075 per GB for the next 20 TB per month, and $0.05 per GB for the next 50 TB per month for both storage destinations.
AWS expects that the support for logs in Firehose will help enterprises streamline the delivery of Lambda log to additional destinations such as Amazon OpenSearch Service, HTTP endpoints, and third-party observability providers, such as Splunk, Sumo Logic, and New Relic.
Earlier this week, the cloud service provider added support for additional cost metrics and filtering capabilities to its finance management tool, Budgets, which is designed to help enterprises keep track of their expenditure by setting custom usage thresholds on various services individually or for the entire enterprise.
Just days earlier, AWS updated the Data Automation capability inside its generative AI service Amazon Bedrock to further support the automation of generating insights from unstructured data and bring down the development time required for building applications underpinned by large language models (LLMs).
{kind=link}
Amazon launches Nova Premier, its ‘most capable’ AI model yet 2 May 2025, 2:47 pm
Amazon Web Services (AWS) has launched Nova Premier, its most advanced AI model to date, via Amazon Bedrock. Designed for enterprise use, the model targets complex, multi-step workflows and supports model distillation, enabling smaller models to inherit its capabilities with improved efficiency and reduced cost.
{kind=link}
Leaderboard illusion: How big tech skewed AI rankings on Chatbot Arena 2 May 2025, 12:55 pm
A handful of dominant AI companies have been quietly manipulating one of the most influential public leaderboards for chatbot models, potentially distorting perceptions of model performance and undermining open competition, according to a new study.
{kind=link}
Experiments in JavaScript: What’s new in reactive design 2 May 2025, 11:00 am
Experimentation is the name of the game in front-end JavaScript development, and reactive frameworks like Angular, React, Vue, and Svelte are the nexus for innovation in modern web UIs. Keeping an eye on that landscape helps keep your perspective fresh while ensuring you don’t miss out on important developments that could improve your workflow and the performance of your apps.
This month’s JavaScript Report has you covered, with both a comparison of the top frameworks and a closer look at the major new features in Angular 19. We’ll also dig into the React compiler (now in release candidate stage 1) and a collection of experimental features proposed for React. And you’ll get a glimpse at OXC, the new Rust-based JavaScript tool set from Evan Yu—creator of Vue and Vite, among other projects.
Top picks for JavaScript readers on InfoWorld
Catching up with Angular 19
Angular is in the midst of a drive to become more developer-friendly, more powerful, and faster than ever. Here’s a look at the major features in the latest release, including incremental hydration, improved server routes, better signals integration, and a performance-boosting engine refactor.
Comparing Angular, React, Vue, and Svelte
Keeping up with the big ideas emerging in front-end JavaScript framework design is almost a full-time job. This comparison has you covered with highlights from four of the best.
Is the React compiler ready for prime time?
React’s compiler has reached release candidate stage 1, bringing it closer to general availability. Now is a good time to get to know this important new player in the React ecosystem.
Why cubicles are a software development anti-pattern
Developers, including JavaScript developers, generally really don’t like cubicles—or should we say, “concentration-cancelling workspaces”?
More good reads and JavaScript updates elsewhere
The JavaScript Oxidation Compiler
If you like JavaScript, it’s a good idea to keep an eye on Evan Yu, creator of Vue and Vite. Now he’s up to something new, with a Rust-based JavaScript tool set built for speed. OXC is worth a look.
Detecting and mitigating an authorization bypass vulnerability in Next.js
Sonatype’s recently announced discovery of 18,000 open source malware packages in the software supply chain was a stark reminder that developers are a malware target, too. Now is a good time to secure your Next.js installation.
React view transitions and more
The React development team walks through several experimental features and improvements in this post, including a first look at the new view transitions API.
{kind=link}
Public cloud providers get into the chip market 2 May 2025, 11:00 am
The world of public cloud computing is at an inflection point. Cloud providers face significant challenges amid a global surge in demand for GPUs, driven by artificial intelligence and other data-intensive workloads. There is no easy path, given the shortages and the rising demand. So, what can be done? When in doubt, build your own.
The GPU shortage, compounded by pandemic-era supply chain disruptions and increased competition for high-end chips, has forced public cloud giants to turn inward. Companies like Microsoft, AWS, and Google are no longer settling for off-the-shelf hardware; instead, they are leading the charge in custom chip development. This shift, initially a response to immediate shortages, has the potential to reshape the cloud industry and the broader CPU and GPU markets. As cloud providers dive deeper into chip innovation, their advances will accelerate competition and disrupt long-standing industry dynamics.
The rise of custom silicon
Public cloud providers have always been innovators. Take Microsoft, for example. During its annual Ignite conference, the company revealed two new chips that promise to push the boundaries of what’s possible on the Azure platform. The Azure Boost DPU (data processing unit) is designed for optimized data handling to support AI workloads more efficiently. At the same time, the Azure Integrated HSM (hardware security module) enhances security for encryption and key management processes. Both aim to address the cloud ecosystem’s specific challenges—performance optimization and security—while relying less on traditional GPU and CPU supply chains.
Microsoft isn’t the only one making waves. AWS has already established itself with custom chips such as Trainium for machine learning training, Inferentia for inference workloads, and its Nitro system for advanced virtualization and security. Google brought its Tensor processing units (TPUs) to market years ago as a custom solution for machine learning tasks. Combined, these innovations are not just filling the gap left by conventional GPUs, they’re redefining how we think about workloads at scale.
Other industry players are following suit. Nvidia, best known for its GPUs, has introduced Bluefield chips, and AMD is leaning into its Pensando portfolio. The result is an ecosystem increasingly reliant on custom accelerators tuned to specific tasks—a far cry from the days when a handful of brands dominated the chip market.
Fixing GPU shortages and more
The overarching motivation for investing in custom silicon is clear: Traditional GPUs, while powerful, are often too power-hungry, expensive, and general-purpose to handle the nuanced demands of modern cloud computing. With more demand than supply of Nvidia’s GPUs, for instance, alternative solutions like custom-designed chips offer more control over price-performance ratios, energy efficiency, and cooling requirements.
Furthermore, custom chips allow for the creation of highly specialized systems that outperform general-purpose processors for specific workloads. Security chips such as Microsoft’s HSM, AWS’s Nitro, and Google’s Titan, for example, demonstrate how tailored hardware can solve niche problems, such as reducing latency in encryption tasks or validating system health from the hardware level. By moving security into dedicated silicon, these providers are enhancing scalability, cutting costs, and improving customer trust—three imperatives in today’s competitive cloud market.
This is also a workaround for the geopolitical issues many industries are facing. Custom chips allow public cloud providers to sidestep many of the production roadblocks facing traditional CPU and GPU vendors. Existing supply chains are grappling with American trade disputes with China, the fact that most semiconductor production is concentrated in Asia, and tariffs on high-tech goods. By taking their silicon fabrication needs into their own hands and innovating with partners, cloud providers gain an edge.
This will have profound consequences for the larger CPU and GPU industries. First and foremost, direct competition will increase. Intel, AMD, and Nvidia had a virtual monopoly on the chip market for years. But as public cloud providers expand their custom silicon offerings, an entirely new tier of competition emerges. Cloud providers are essentially becoming chipmakers.
Indirect competition is also ramping up. Competition from cloud providers pressures traditional chip companies to innovate faster as they defend their market share. If AWS or Google can provide next-gen computing power without relying on Nvidia, how long will other enterprises continue to pay premium prices for legacy hardware? Likewise, the hyperscalers’ expertise in specialized silicon design could lead to a broader trend: enterprises building tailored hardware in collaboration with semiconductor manufacturers.
It doesn’t stop there. Custom silicon may drive innovation outside the cloud industry entirely. Consider the potential for these chips to impact automotive automation, robotics, or even personal devices. Furthermore, because custom accelerators prioritize efficiency and specialization, they could help mitigate the environmental costs associated with high-end GPU manufacturing and operations, creating a net benefit for industries beyond tech.
Expanding the silicon race
In-house chip development comes with its own set of challenges. Designing, testing, and producing semiconductors is no small feat. Cloud providers are entering a capital-intensive, high-stakes arena typically dominated by firms like TSMC and Samsung. To succeed, they must partner closely with manufacturers and chip architects to ensure their specialized designs can be mass-produced quickly and affordably.
More importantly, regulatory scrutiny may soon become a concern. As hyperscalers acquire more control over their hardware ecosystems, questions of anti-competitive behavior will naturally arise. How these companies address these concerns without stifling innovation will be pivotal to the future of custom chips.
The growing investment in custom chips represents a radical shift for both the cloud and semiconductor industries. In many ways, it signals the beginning of an era when hyperscalers dictate cloud computing innovations and fundamentally reshape underlying hardware ecosystems. This transition won’t just enhance cloud platforms with better performance, security, and scalability—it could also open doors for indirect innovation, new partnerships across industries, and solutions to persistent trade hurdles.
{kind=link}
JetBrains AI Assistant panned in JetBrains Marketplace 2 May 2025, 1:05 am
Despite having been downloaded nearly 23 million times, the JetBrains AI Assistant has received bad reviews on the company’s JetBrains Marketplace website, prompting JetBrains to remove some of the reviews.
Unveiled in December 2023, the JetBrains AI Assistant rates only 2.3 stars out of a possible five stars on the company’s ratings system, with 851 total ratings as of May 1. “I’ve been a long-time user of JetBrains IDEs and generally appreciate the thoughtful tooling they offer,” reviewer Haso Keric wrote. “Unfortunately, the AI Assistant doesn’t live up to the same standard. It feels bolted on rather than integrated, and it quickly becomes more of a novelty than a productivity tool.” Several reviewers described the tool as having uneven auto-completion performance, while several others said that their reviews had been removed. “My previous comment was deleted without any specific reason. Jetbrains seems to be deleting negative reviews, which destroyed my confidence and trust in this company. They do not value their customers and their feedback anymore,” reviewer Juraj Nemec wrote.
In a Reddit post under the name of mutegazer, a JetBrains representative said some reviews were removed because they involved an already-solved issue, while others were removed because of policy violations such as swearing. Negative or positive posts about current AI Assistant behavior have remained, mutegazer wrote. The JetBrains rep acknowledged that the company could have handled the removals better. “Nuking several reviews at once without a heads-up looked shady,” mutegazer wrote. “At least, we should’ve posted a notice and provided more details to the authors.”
Also, mutegazer revealed JetBrains’ next steps, promising the company would:
- Consider the options to approach this whole case of major updates differently.
- Explore per-version reviews or mark reviews as “Resolved” and link to related YouTrack issues instead of deleting.
- Commit to clearer, faster communications in general, and especially whenever we moderate content.
The JetBrains rep also urged reviewers to keep the feedback coming. The JetBrains AI Assistant has received some positive reviews. “I think this plugin is really great, I find it useful and it became a must have in my development toolkit. Thanks,” reviewer Jonathan Gafner wrote. “Really, I love this. Thanks,” reviewer Dharmendra Kumar Singh wrote, giving the AI Assistant five stars. Another five-star reviewer, Jochen Issing, wrote, “I have just used your AI and I was amazed.”
{kind=link}
Redis bets big on an open source return 1 May 2025, 5:48 pm
Today, Redis makes a dramatic return to its open source roots, offering Redis 8 under the AGPLv3 license. The shift follows a similar move by Elastic in August 2024 and completes the company’s somewhat circuitous licensing path. In both cases, I suspect that neither company ever really wanted to leave open source. The irony is that the very thing that most threatened to hurt their businesses actually helped them: forking.
Redis’ license change “achieved our goal,” writes Redis CEO Rowan Trollope. “AWS and Google now maintain their own forks.” How is this a good thing? Because, Trollope told me in an interview, “We’re on a level playing field now; we get to compete on product.” With AWS and Google focused on developing the Valkey fork of Redis (Microsoft has partnered with Redis), Redis can focus on shipping the best possible product. Trollope is enthusiastic about the prospect: “Who’s going to ship the best stuff? We have the creator [Salvatore Sanfilippo] of Redis behind us, alongside the team who built it. We’re already seeing that pay off in things like vector sets, a new native data type for Redis that Salvatore developed. I’ll bet on that team any time.”
In other words, changing licenses may not have been intended to spur the clouds to fork Redis (or Elasticsearch), but it may end up being the best thing for everyone involved, including customers.
Forking is good for you
I recently wrote about the success of OpenTofu (a fork of HashiCorp’s Terraform), and OpenSearch (a fork of Elastic’s Elasticsearch). I’ve yet to write about Valkey, but there would be plenty of good things to say, given former Redis maintainer (and AWS engineer) Madelyn Olson’s involvement and its growing community. In the past year, it has garnered nearly 20,000 GitHub stars, over 750 forks, and more than 5 million Docker pulls. Despite the success of these forks, or perhaps because of them, Elastic, Redis, and HashiCorp are thriving.
Huh?
Redis’ license changes and, by extension, the Valkey fork, Trollope tells me, “[haven’t] had any effect on our business.” Indeed, he says, “We’ve had record growth since we switched the license.” Though this seems superficially counterintuitive, it’s actually common sense: The more the clouds have focused on the forks, the clearer the product differentiation for Redis (and Elastic and HashiCorp). “We accomplished what we set out to do, which is for cloud providers to stop profiting off our innovation without giving anything back,” Trollope notes.
Not everyone agrees with this, nor do they need to. RedMonk cofounder James Governor suggests such license changes amount to treating open source like a “short-term tactic” for marketing and distribution purposes, rather than a long-term software development methodology. Trollope disagrees. Although he acknowledges the move to AGPLv3 will help the company “retrench ourselves in the community in order to build back any trust we might have lost,” he’s emphatic that “there’s no one better to carry the mantle for open source Redis than the team that built it.”
Governor and others might suggest that a foundation, not a company, would be a better steward for an open source project, and they’d find plenty of case studies to support their argument: Linux, Kubernetes, PostgreSQL, etc. Still, there are strong counterexamples of companies (Oracle managing MySQL) or individuals (OBS) who build great open source products without the benefit of community contributions. Personally, I love the foundation approach, but open source succeeds in part because of its diversity (in licensing, governance structures, etc.).
Developers can choose
Having options is the point, right? Open source is always about choice. In a previous interview Trollope told me that “what [developers] really care about is capability: Does this thing offer something unique and differentiated … that I need in my application?” With the rise of Valkey, developers have an increasingly interesting choice to make. Valkey’s developers describe it as a “high-performance key/value data store that supports a variety of workloads such as caching [and] message queues.” Redis, by contrast, describes itself as a “real-time data platform,” positioning itself within the emerging AI tech stack. The Valkey community seems less focused on AI, at least for now, preferring instead to drive significant improvements in scalability and memory efficiency, things that improve Valkey’s core reliability and performance for cloud deployments.
This is a feature, not a bug. Different developers (and their respective employers) want different things. The Valkey community will build a great product, and Redis will build a great product. Both open source. Everyone wins.
Would Trollope have preferred a smoother path to this point? Of course. “We…didn’t meet the open source community—and our community—where they are. I wish we had done better.” Fortunately, “that’s something that Salvatore has helped with a lot,” both giving us “a credible voice in the open source community” while also being “an incredible advocate for the company.” Oh, and he’s also an exceptional engineer: Sanfilippo is responsible for introducing Redis’ first new data type in years (vector sets). He’s a behind-the-scenes heavy influence on the thinking that led the company back to an open source license, which has meant they can now fold in features from the Redis Stack modules (search, JSON, Bloom filters, etc.) to unify their internal development processes while creating a one-stop, real-time data platform.
“We think [changing to AGPLv3 is] the right thing to do for our users, and it’s the right strategic direction for the company,” says Trollope. It should ensure an even better Redis, while the Valkey fork, steered by an increasingly diverse array of contributors from Alibaba, Google, Ericsson, Huawei, Tencent, AWS, and others, promises to give developers a strong alternative. Neither Redis nor Valkey are guaranteed success. Both bring strengths and weaknesses. Developers (and their enterprise employers) will ultimately decide, but at least they now have a clear choice between two great alternatives.
{kind=link}
JDK 25: The new features in Java 25 1 May 2025, 5:42 pm
Java Development Kit (JDK) 25, a planned long-term support release of standard Java due in September, now has five features officially proposed for it. The latest feature is flexible constructor bodies, which was previewed in the three prior versions of Java.
Flexible constructor bodies was designated as targeted for JDK 25 this week, according to the JDK 25 reference implementation page. Previous features designated for JDK 25 include module import declarations, compact source files and instance main methods, a preview of an API for stable values, and removal of the previously deprecated 32-bit x86 port. Module import declarations and compact source files and instance main methods were previewed in previous JDKs and are set for finalization in JDK 25.
JDK 25 comes on the heels of JDK 24, a six-month-support release that arrived March 18. As a long-term support (LTS) release, JDK 25 will get at least five years of Premier support from Oracle. JDK 25 is due to arrive as a production release on September 16, following rampdown phases in June and July and two release candidates planned for August. The most recent LTS release was JDK 21, which arrived in September 2023.
Flexible constructor bodies was previewed in JDK 22 as “statements before super(…)” as well as in JDK 23 and JDK 24. The feature is intended to be finalized in JDK 25. In flexible constructor bodies, the body of a constructor allows statements to appear before an explicit constructor invocation such as super (…) or this (…). These statements cannot reference the object under construction but they can initialize its fields and perform other safe computations. This change lets many constructors be expressed more naturally and allows fields to be initialized before becoming visible to other code in the class, such as methods called from a superclass constructor, thereby improving safety. Goals of the feature include removing unnecessary restrictions on code in constructors; providing additional guarantees that state of a new object is fully initialized before any code can use it; and reimagining the process of how constructors interact with each other to create a fully initialized object.
Module import declarations, which was previewed in JDK 23 and JDK 24, enhances the Java language with the ability to succinctly import all of the packages exported by a module. This simplifies the reuse of modular libraries but does not require the importing code to be in a module itself. Goals include simplifying the reuse of modular libraries by letting entire modules be imported at once; avoiding the noise of multiple type import-on-demand declarations when using diverse parts of the API exported by a module; allowing beginners to more easily use third-party libraries and fundamental Java classes without having to learn where they are located in a package hierarchy; and ensuring that module import declarations work smoothly alongside existing import declarations. Developers who use the module import feature should not be required to modularize their own code.
Compact source files and instance main methods evolves the Java language so beginners can write their first programs without needing to understand language features designed for large programs. Beginners can write streamlined declarations for single-class programs and seamlessly expand programs to use more advanced features as their skills grow. Likewise, experienced developers can write small programs succinctly without the need for constructs intended for programming in the large, the proposal states. This feature was previewed in JDK 21, JDK 22, JDK 23, and JDK 24, albeit under slightly different names. In JDK 24 it was called “simple source files and instance main methods.”
Stable values are objects that hold immutable data. Because stable values are treated as constants by the JVM, they enable the same performance optimizations that are enabled by declaring a field final. But compared to final fields, stable values offer greater flexibility regarding the timing of their initialization. A chief goal of this feature, which is in a preview stage, is improving the startup of Java applications by breaking up the monolithic initialization of application state. Other goals include enabling user code to safely enjoy constant-folding optimizations previously available only to JDK code; guaranteeing that stable values are initialized at most once, even in multi-threaded programs; and decoupling the creation of stable values from their initialization, without significant performance penalties.
Removal of the 32-bit x86 port, which also is proposed to target JDK 25, involves removing both the source code and build support for this port, which was deprecated for removal in JDK 24. In explaining the motivation for the removal, the proposal states that the cost of maintaining this port outweighs the benefits. Keeping parity with new features, such as the foreign function and memory API, is a major opportunity cost. Removing the 32-bit x86 port will allow OpenJDK developers to accelerate the development of new features and enhancements.
Other features that could find a home in JDK 25 include a key derivation function API, scoped values, structured concurrency, and primitive types in patterns, instanceof, and switch, all of which were previewed in JDK 24. The vector API, which was incubated nine times from JDK 16 to JDK 24, also could appear in JDK 25.
{kind=link}
Download the ‘AI-Savvy IT Leadership Strategies’ Enterprise Spotlight 1 May 2025, 5:00 pm
Download the May 2025 issue of the Enterprise Spotlight from the editors of CIO, Computerworld, CSO, InfoWorld, and Network World.
{kind=link}
Page processed in 0.378 seconds.
Powered by SimplePie 1.3.1, Build 20130517180413. Run the SimplePie Compatibility Test. SimplePie is © 2004–2025, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.